Projects
time; is no time at all

If all you have is a hammer, everything you see is a nail-
That if we're content with knowing only what we know, we are but a prisoner who yearns the periscope
My goal exists in exploration - to free ourselves of the bounds of words of men and women who died long ago. And to find neoteric thought, to conjure new knowledge that only waits to exist
CONTACT ME
glueeestain@gmail.com
follow me on substack ↗
GLUEgle Glass
The inspiration for this project is Google's "Google Glass" schema developed in the early 2010's which fell off due to minimal usability.
I am attempting to reignite the flame by now integrating AI with a similar model fixed for a universally-niche use case.
Watch this quick demo video.
I have created a system which uses a combination of Embedded Systems, Computer Vision, OCR (Optical Character Recognition), and NLP techniques to fulfill tasks.
The hardware consists of of a miniature 5MP camera, an e-ink display, a Raspberry Pi Zero W microcontroller, and other wirings.

The software stack uses Python and incorporates a variety of libraries and APIs; OpenCV for image capture, Tesseract for OCR, Wikipedia/Dictionary API and a Hugging Face AI model for text completion.
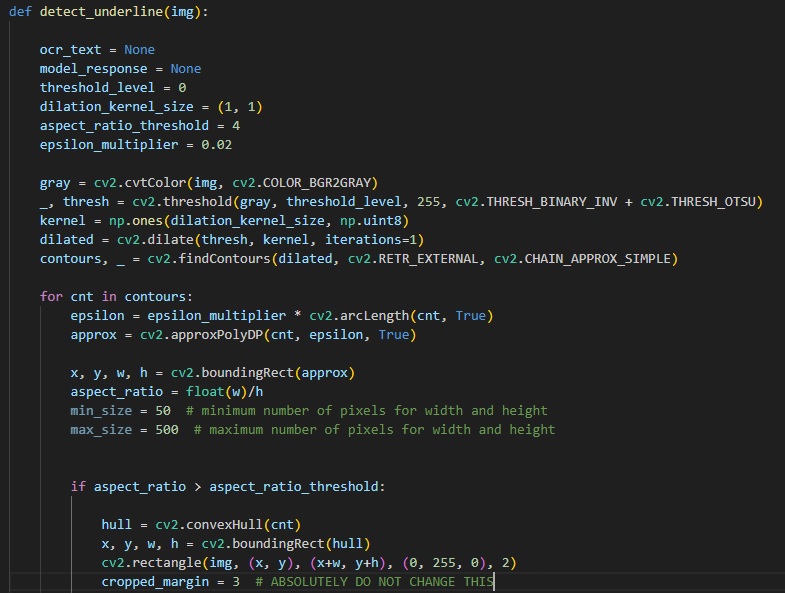
Quick sample of the OpenCV pre-processing optimization before being sent to OCR
The workflow is as follows:
- 1. The camera captures a live feed
- 2. OpenCV processes the images to detect underlines
- 3. OCR is applied to recognize the underlined text
- 4. The recognized text is sent as a prompt to the AI backing
- 5. The AI's response is displayed on the e-ink screen
More specifically, it is capable of reading text from a screen AND also text from a book irl. The software I've developed uses a contouring-locator to find underlined text to be sent for a response.

As shown, book text is translated to readable OCR text via Adaptive Thresholding, Gaussian Blurring, Binary Filtering before being sent to OCR. This pre-processing method is extremely lightweight.
The system is designed to be modular, allowing for future optimizations in speed, accuracy, and the like. Lowered frame rates, screen updates, and multithreading have done well to optimize a 512mb ram ... Lol!
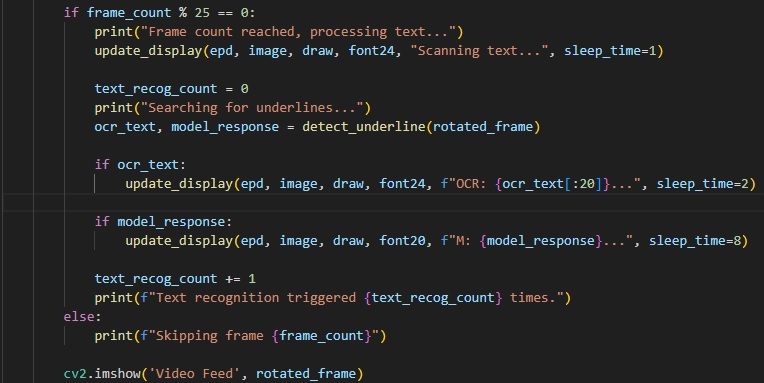
Results are displayed on screen like so! This was the response from the Demo Video.

This project opens doors for a multitude of applications, having breathed life once again to a project I believe Google should look back into once more - especially with the flux of AI! With my assistance, if needed!
This initiative serves as a stepping stone towards creating a more interactive and AI-integrated environment, revolutionizing the way we interact with textual information in the physical world.
There is a more that is involved in the software behind this project that I am not displaying here for reasons of brevity. For further inquiry, send me an email!
Back
Writing Style Emulator (NLP)
The main purpose of creating this program was to develop a "Bot" that replicates and emulates my specific and niche writing style after prompting. It has done amazing thus far.
The bot is currently being trained on over 2 million lines.
Overall, it is an advanced Natural Language Processing (NLP) system designed to stylize text based on predefined thematic categories. It uses several interconnected components to process and transform the input text, aligning it with specific stylistic attributes. Responses are generated with an outdated text-transformer- then dissected, stylized, and reconstructed with my modules.
The program is designed to be modular, allowing for the addition of new components and the modification of existing ones. The current version includes four modules: Trainer, Organizer, Synonymizer, and Mundaner.
By first loading the bot to train with a large corpus of text that I have written, and other authors I take inspiration from - it serves as the large body of text stylization required to assemble the bot's neural network. It is able to handle entire textbooks of information, e-libraries of information.
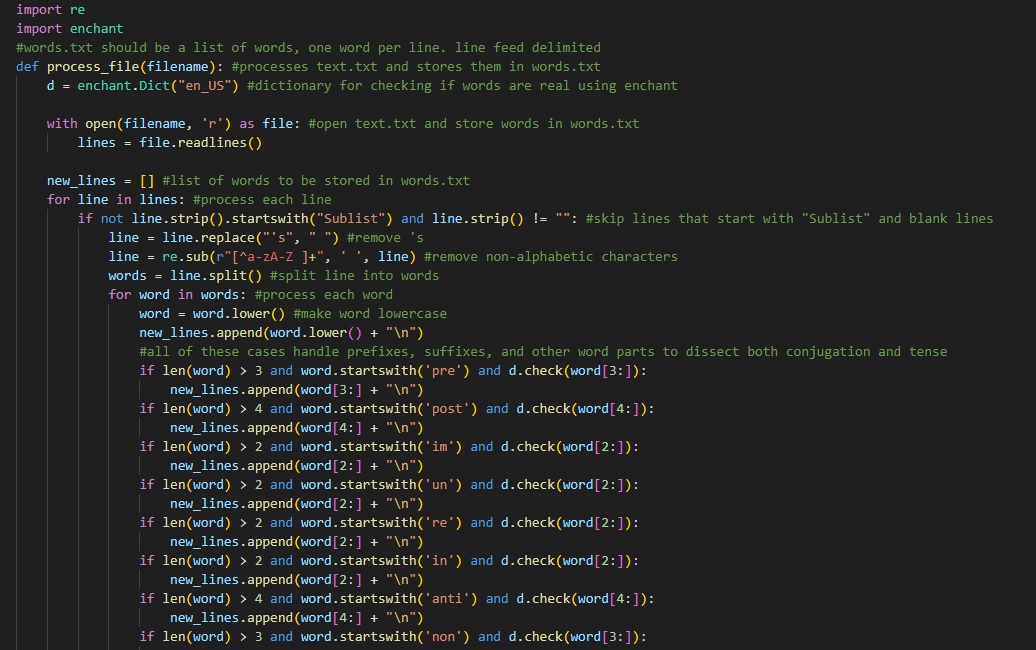
The Organizer module processes that given text file, extracting and identifying words, suffixes, and prefixes. It uses the enchant library to verify word legitimacy and produces a refined word list. Additionally, delimits words by line feed for readability.
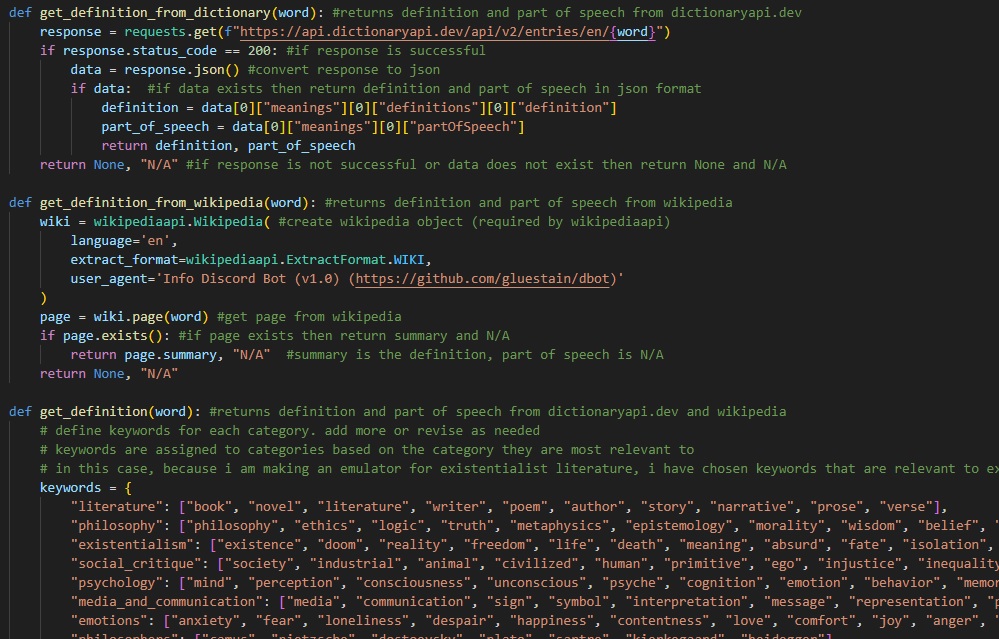
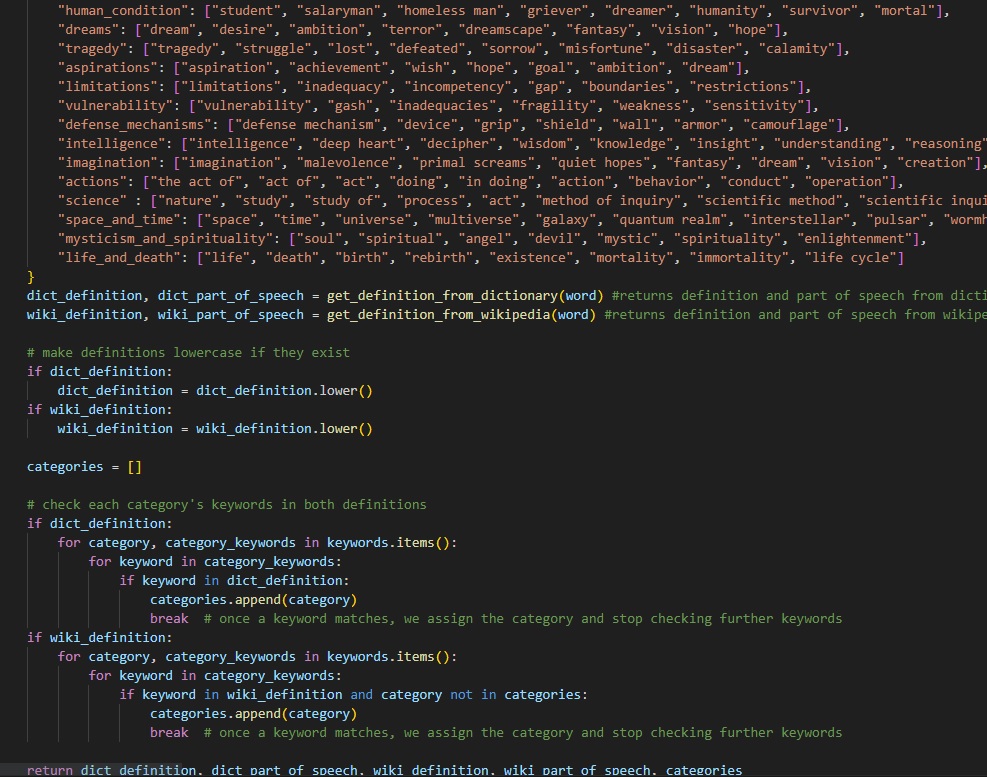
The Trainer module leverages web scraping techniques, dictionary APIs, and Wikipedia content to gather definitions and categorize words. It also maintains a recently-used cache to enhance the randomness in word selection.
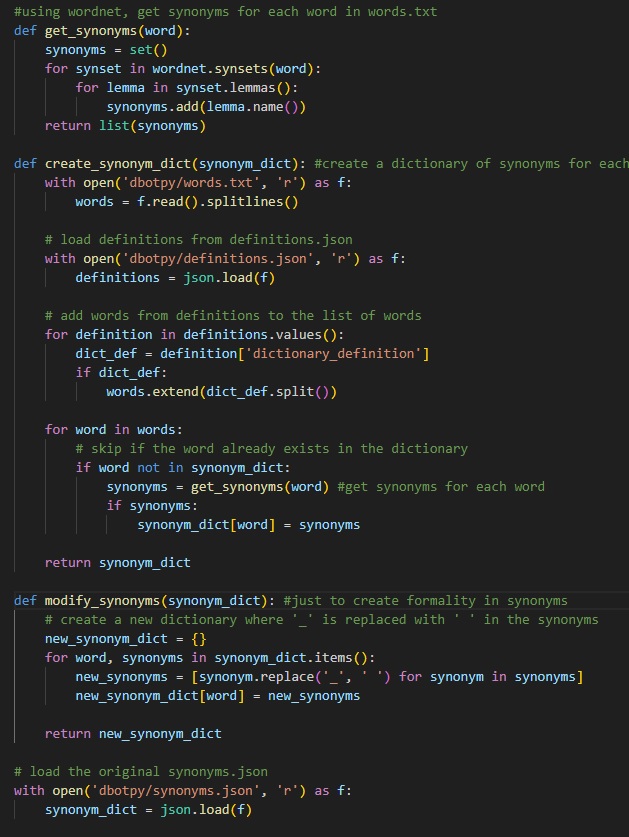
The Synonymizer module constructs a comprehensive synonym dictionary using WordNet. It iterates through the words, fetching synonyms, and adjusting them to fit the context, including special considerations for phrase synonyms.
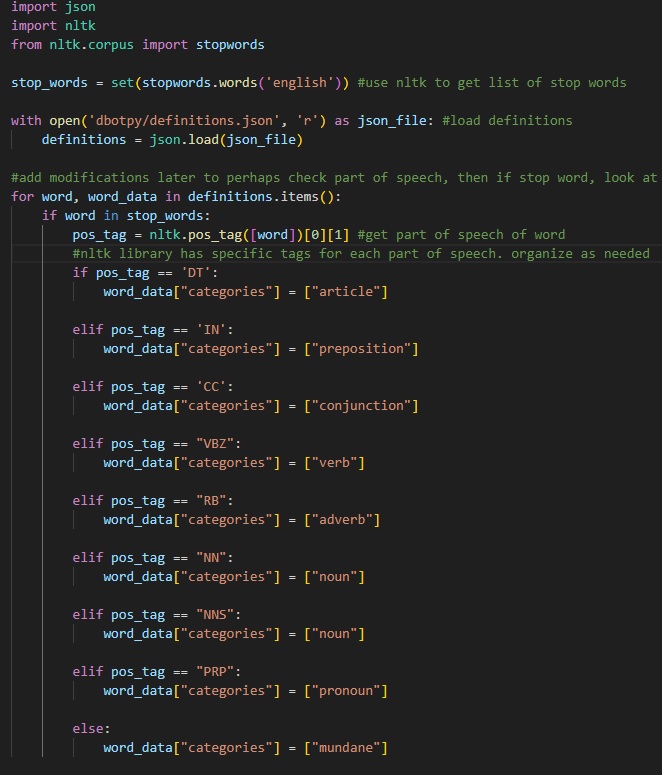
The Mundaner module operates as a tertiary text-processing mechanism, using tokenization and part-of-speech tagging to identify suitable replacements. It integrates words from the definitions and synonyms, prioritizing thematic word replacements and logging the changes.
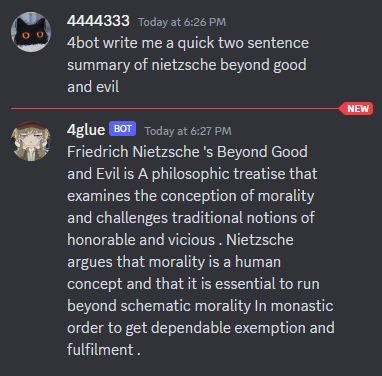
An example output showcasing the transformation of original text into a stylized version. The system's capability to adapt the language according to the theme lends itself to various creative and contextual applications.

All conversations with the bot are also stored in multiple logs, which are also used to further train the bot to learn from previous conversations.
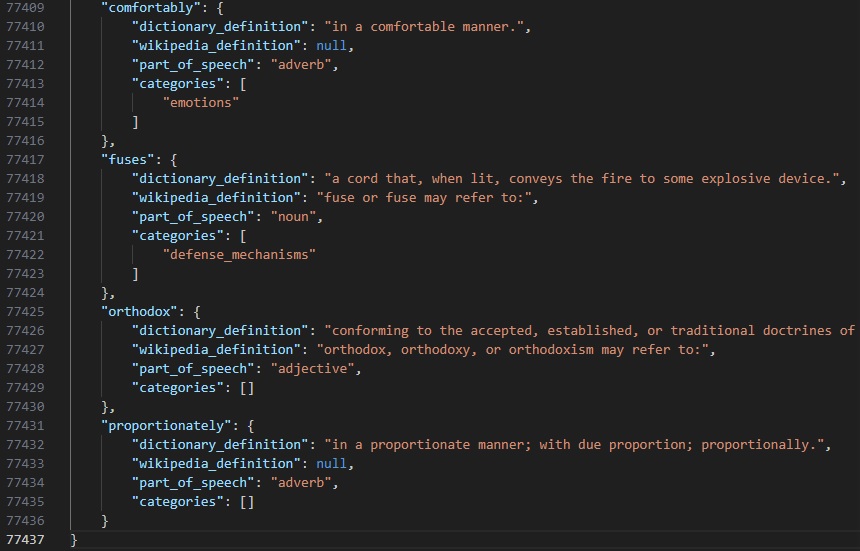
Here is also a sample of what the definition.json (which carries word definitions, part of seech, and categories) file appears like after the execution of the Trainer and Organizer module.
Associated .txt files are used for word storage, definitions, and replacement logs, ensuring a rich and adaptive vocabulary that evolves over time.
Back
C++ RPG
Written in C++, this RPG game was developed with SoulsBorne inspiration
Using the perks of OOP in C++, class elements determine characters, items, and overall function. With a large sum of characters to play as, plethora of items, room events, and abundance of enemies, it is with certainty that every "run" is unique and entertaining
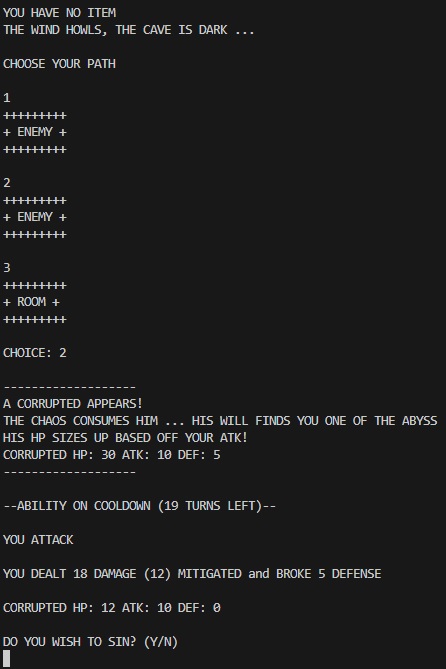
A typical run through of the game looks as so, and being RNG-based, no one game is similar its predecessor
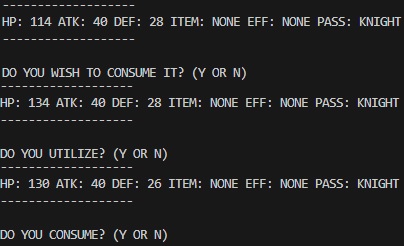
Coupled with multiple interactive sequences, themed around user choices, the player only feels the illusion of control
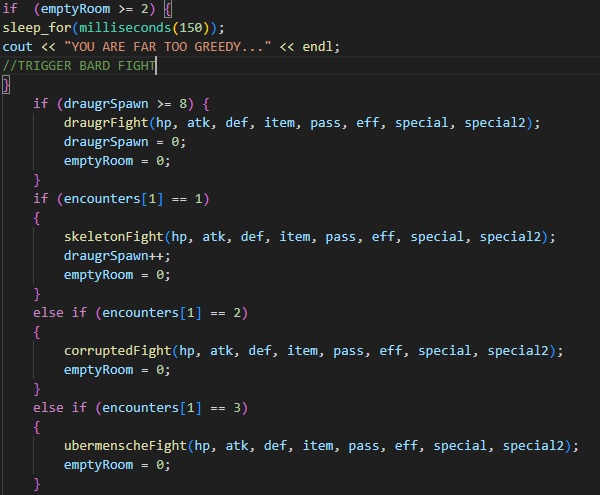
A glimpse of the code that controls the "rooms" which player encounters. Also handled by RNG.
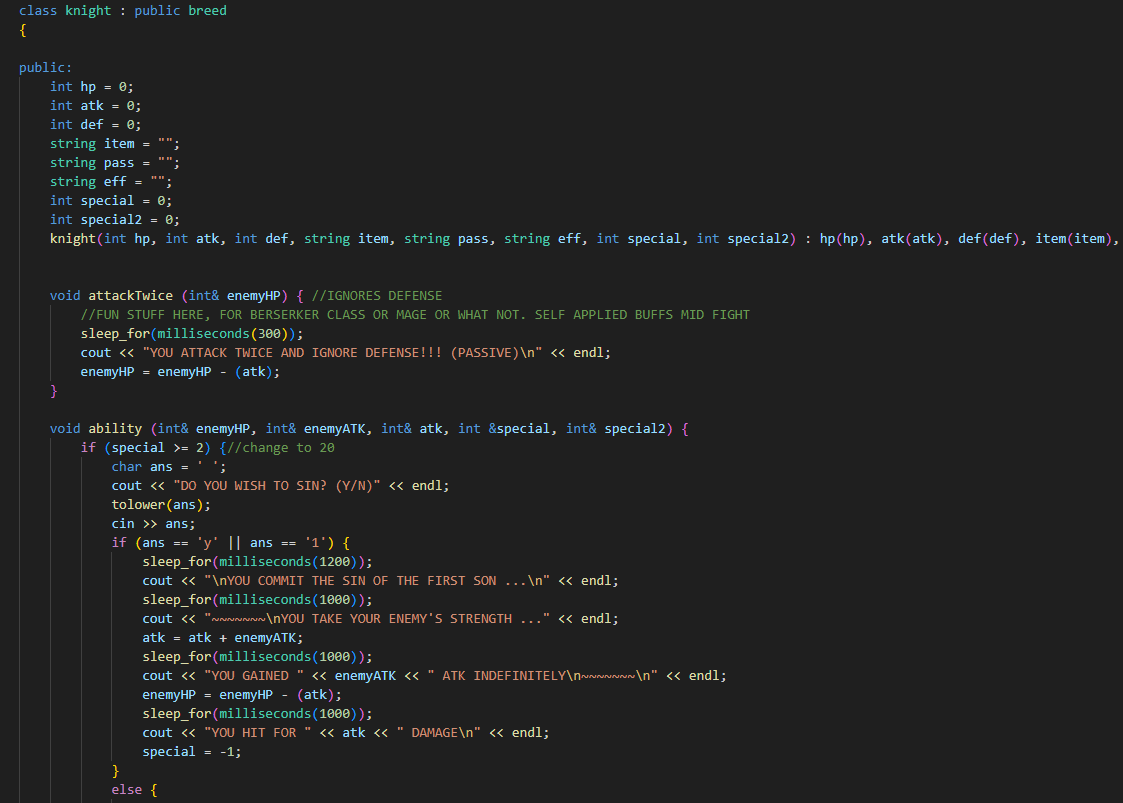
Here is a look into the class elements that handles character selection, and all the data for that character to be altered throughout the playthroughs. It is complete with various class-functions applicable only within selection (or accessed by the selected class). Passive abilities, active abilities, stats, etc., Parameters and their datatypes are specific to their function in the game, i.e, HP is handled by an integer and equipped items are literals (strings).
Back
Python Info Bot
Written in Python, this ML-Infused Discord bot was designed for informational and organizational purposes
Capable of answering historical, scientific, and logic-based questions, the Bot cross references web-scraped data with a modified and rehashed GPT 2.5 model originally sourced by OpenAI
I will document its first use case here by the first preliminary web-scrape, outputted from a stored file (which is later used for reference)
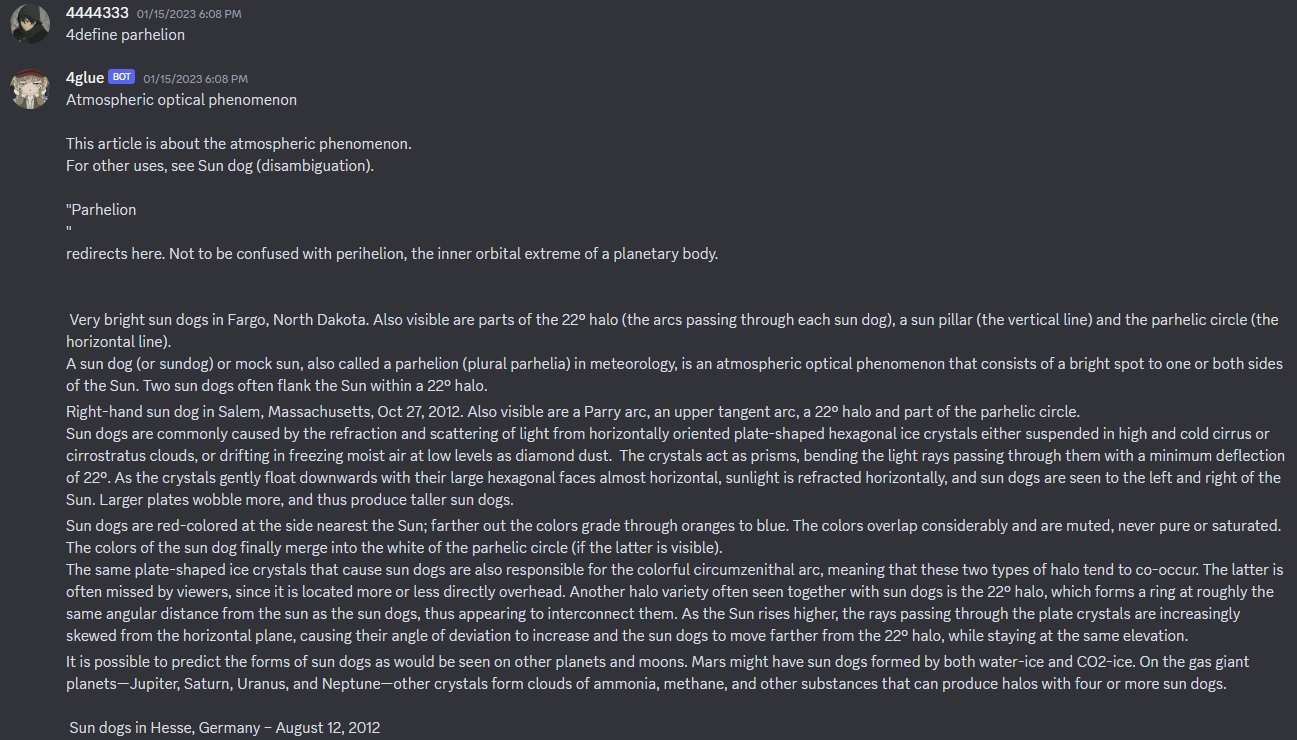
As shown, the bot delivers a heaping load of text relevant to the question and its scope. Generally, is scraped from Wikipedia, WebMD, and Google
Then, another function can be called to refine the data, using medium-light linear regression sorting algorithms to display more specific details. This function implements the GPT2.5 model

Finally, using a wad of parameters to further offset the "crude" state of data, another function can be called to advance the specs. This deploys the GPT2.5 Model and references, sorts, then selects the data generated from the webscrape
Moreso, a snippet into the Python code that develops and runs this program. First, a look at the general overview of command and function calling. As shown, the bot is capable of (in these First Variants) webscraping wikipedia and identifying information based off user input. In a second, unshown variant, it processes all scraped data into a file and validates critical information for further precision. You also see mention of one of the chatbot functions, which is quintessential to the operation. It incorporates the aforementioned GPT2.5 model, generally used for text generation, and rehashes it to be used for text sorting.
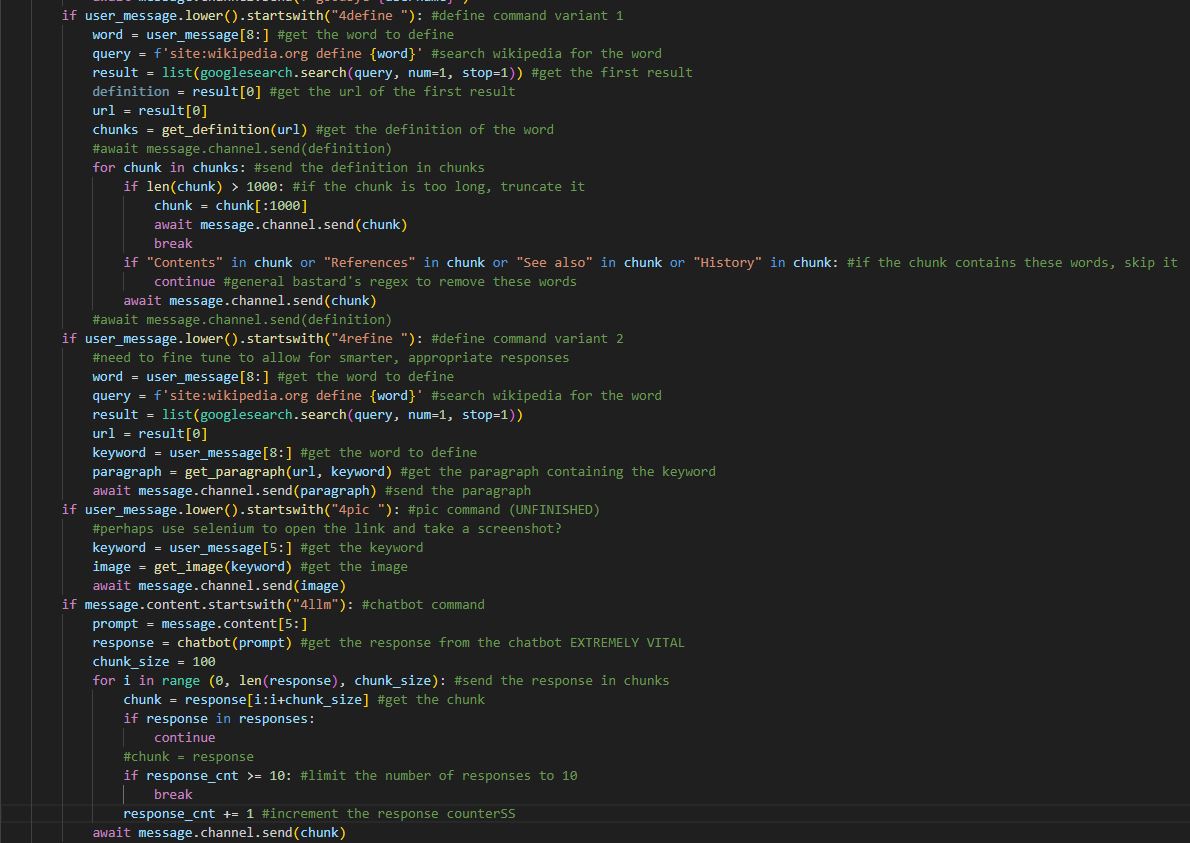
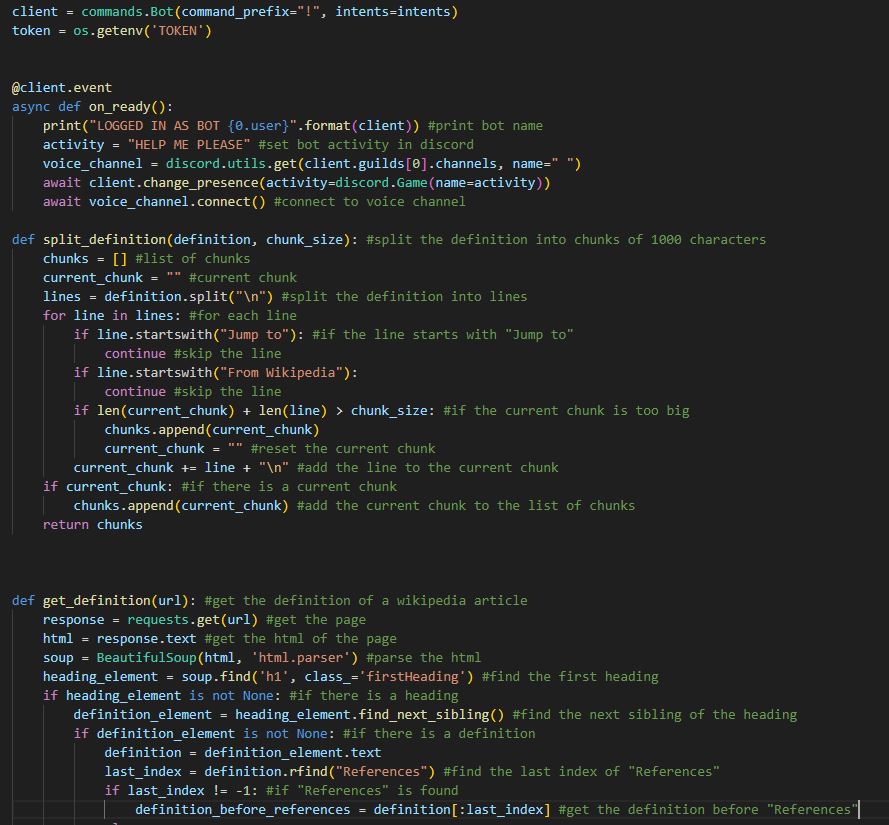
Here is a look into a few of the functions that handle the webscraping. It is a bit crude, but it gets the job done. Raw data is scraped and sorted later. split_definition() is one of the wikipedia scraping variants, and get_definition() is of the file sorter type dedicated to that component. Important functions are of course wrapped in async, as the bot is deployed on Discord, and decorators are in place to handle the command calls.
There is a tad bit I am neglecting to mention about the bot. For further inquiry, send me an email.
Back
ReactJS Data Analysis App
[PROJECT HALTED DUE TO DEPRECATION OF THE EXPO DEVELOPMENT SERVER, AN ESSENTIAL TOOL FOR BUILDING AND DEPLOYING THE PROJECT.]
[UNRESOLVED ISSUES WITH FLASK AND VENVS REMAIN; PLANNING TO REVAMP USING WSGI AND NGINX IN FUTURE ITERATIONS.]
This application was conceived to showcase proficiency in full-stack development, leveraging React Native, JavaScript, Python, and an assortment of libraries.
Primarily targeted towards iOS, the app heavily utilizes React Native's feature set, including seamless scrolling, flexbox for layout design, and a navigation bar.

The app's core concept is centered on the implications of CO2 emissions on temperature, simulated via a Python-manipulated pseudo-database.
Python scripts are used to scrape web data (NOAA and EIA sources) for temperature and CO2 emissions for all US states, which are then organized into a JSON file and subsequently converted into structured CSV files.
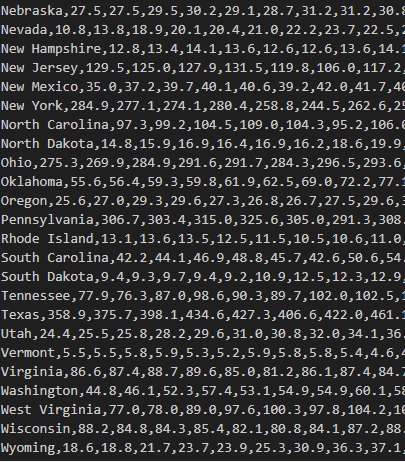
Linear regression is then applied to calculate the impact of each state's CO2 emissions (in million metric tons) on temperature, leveraging libraries such as SKLearn for machine learning, Pandas for data parsing, and NumPy for numerical computations.
OpenWeatherMap's API for current temperature is also used to balance and keep data as empirical as possible. Statistical data is found with algorithms from past ~50 years, and OWM's API is used for accurate, real time temperature data.
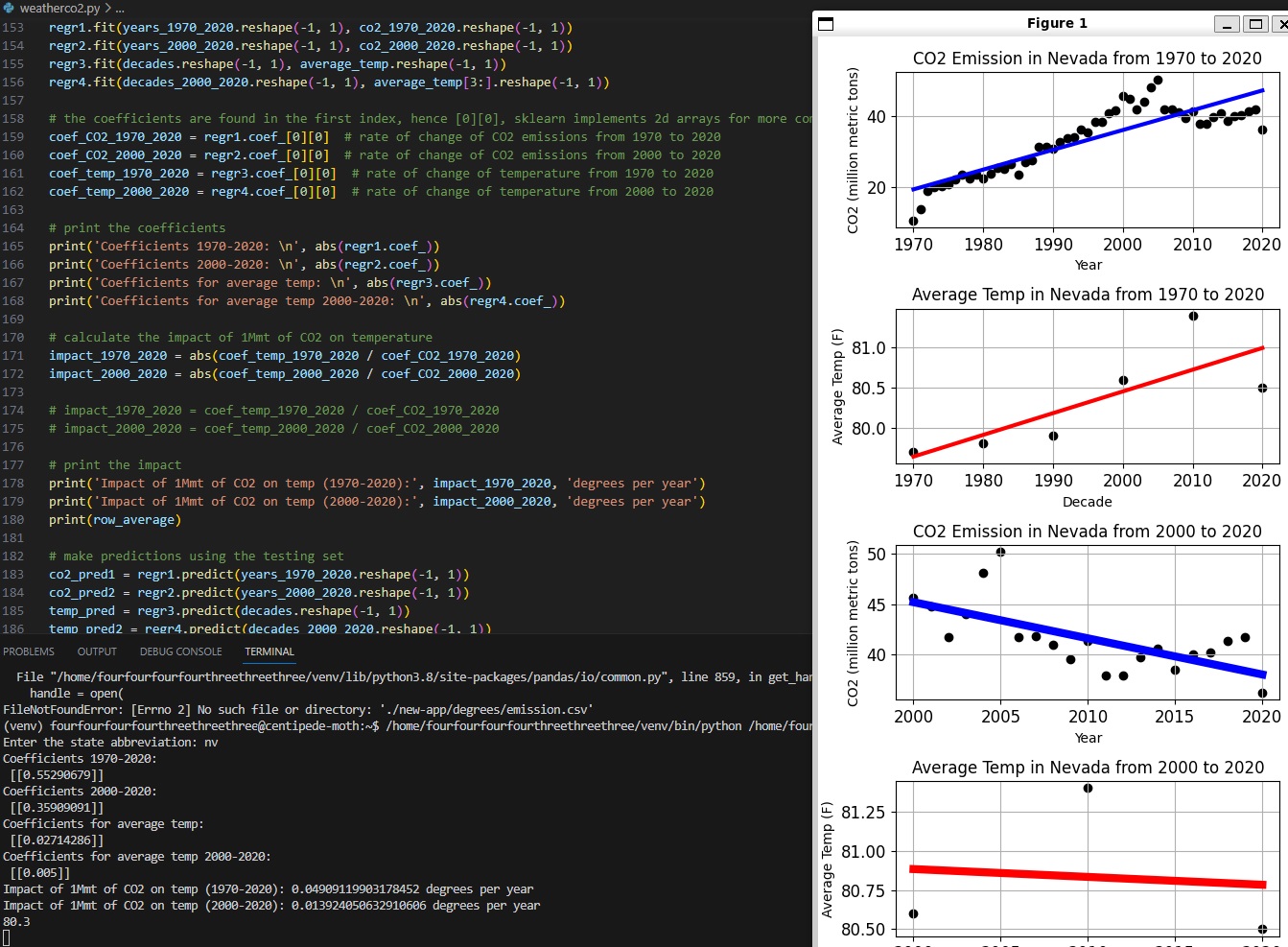
Python's Matplotlib was employed to visualize the models of each state's impact. In order to handle input and ensure proper file I/O and environment management, appropriate OS variables were implemented.
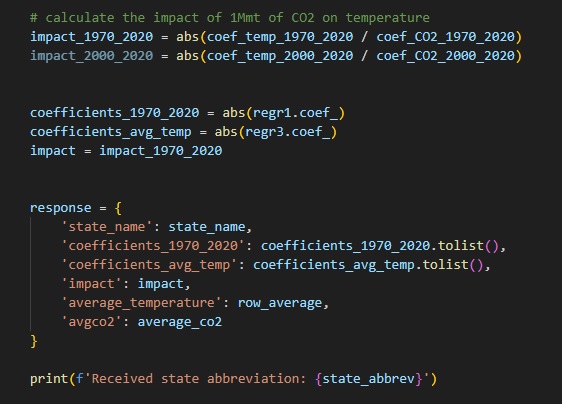
The system accepts input from the React frontend and packages the JSON response accordingly.
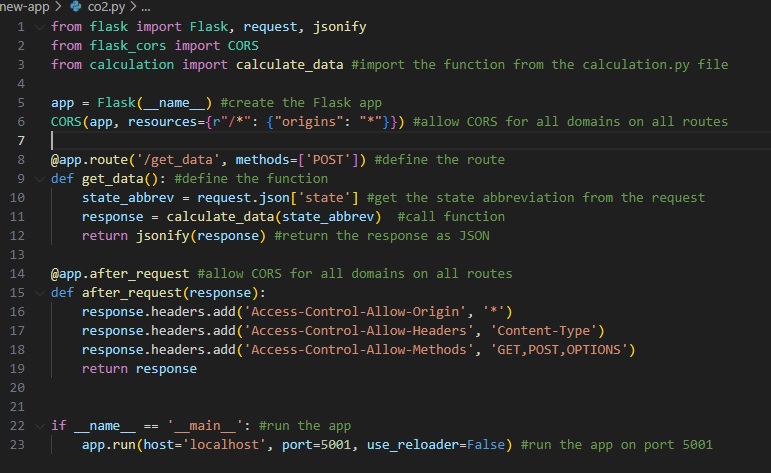
The Flask CORS framework is used to launch the program, which is separated from the calculation file to mitigate potential bugs.
On the frontend, a range of JavaScript variables, functions, and components manage the transmission, organization, and manipulation of packets from the backend.
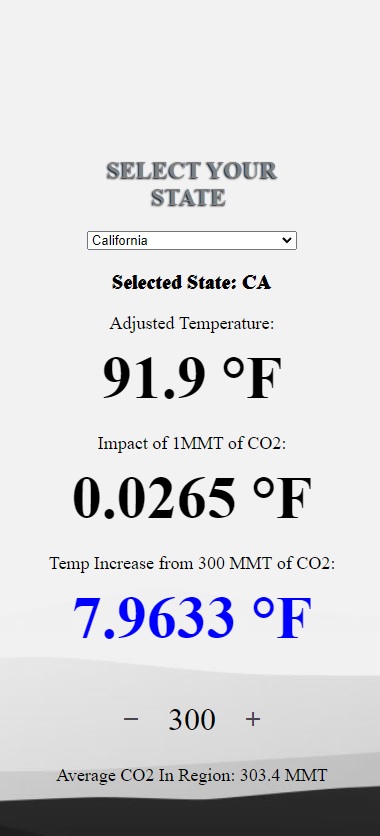
Key display elements include the current temperature of the selected state, the temperature impact of 1 MMT of CO2, user input, and the average CO2 for the region. These are processed and displayed based on the data received from the backend.
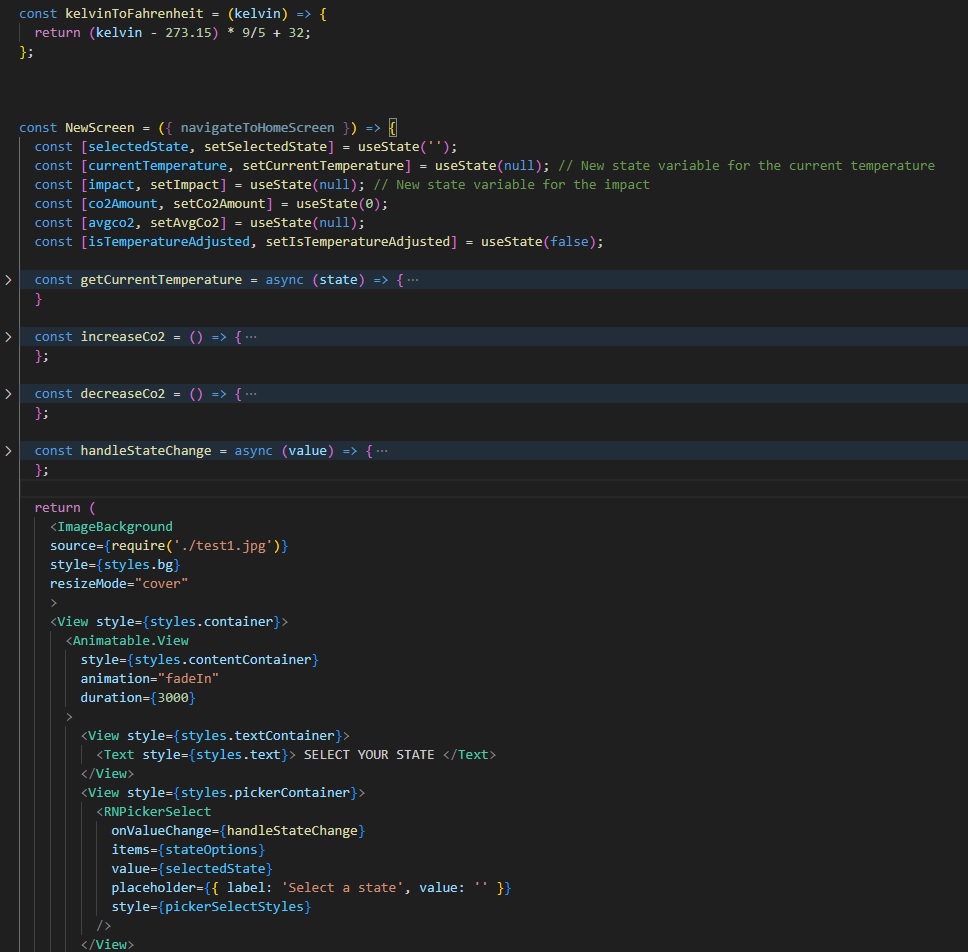
Despite its incomplete status, this project served as a substantial learning experience in programming. While certain components and a level of polish remain absent, I've gained valuable insight from the process, reinforcing the adage of playing the hand one is dealt.
Back
C++ cURL Scraper
Written in C++, this program was designed to locate and display specific chapters(s) of a book found from a website, using the C++ cURL library and regex library.
My primary usage of the regex library was to navigate and organize text found from the HTML within a website's skeleton to pick a part the necessary text for the scrape.

The above is the example output from the program, displaying the preliminary text found at the beginning of a book's chapter. The program is capable of scraping multiple chapters or sections (with modification)
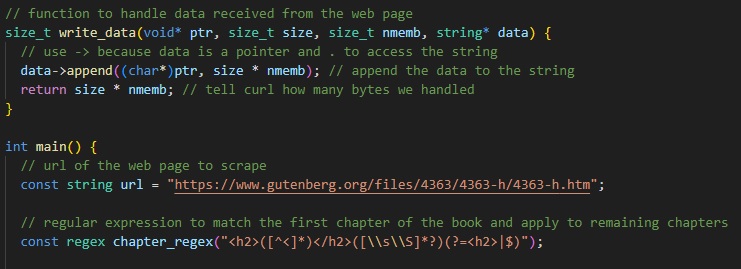
As shown, the scraper first creates a function to be used later alongside a cURL command. This entire program was more a test to my own abilities, and I am aware that there are more efficient ways to do this. Nevertheless, a display of understanding of the cURL syntax especially in relation to the regex library components was my goal.
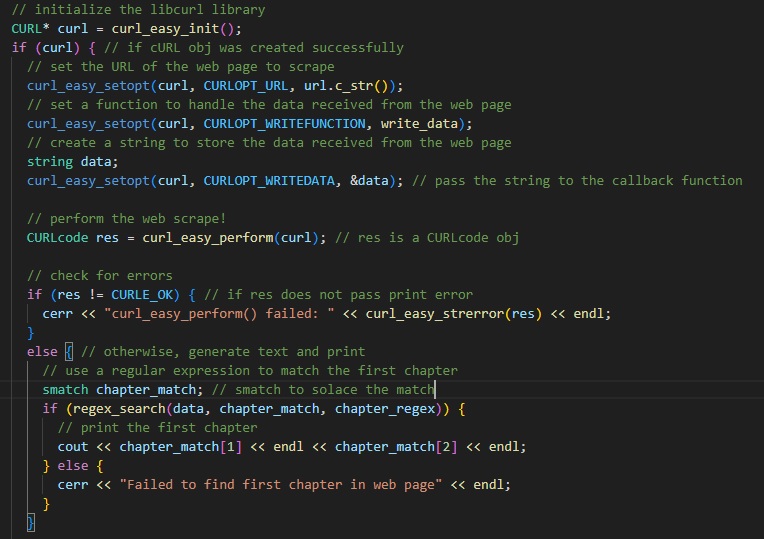
The rest of the code is fairly simple, using functions from the cURL library to commit the scrape. Furthermore, the regex library is used to navigate the HTML skeleton of the website to find the necessary text. And of course, basic error checking and handling is implemented.
Back
Python non-ML Summarizer
This program was a much stronger and more interesting challenge than my other scraper (cURL scraper). Written in Python and implementing the powerful NLTK library, it was a blast to learn and write with.
The best way to document my process in my opinion breaking down the concepts by init and f(x).
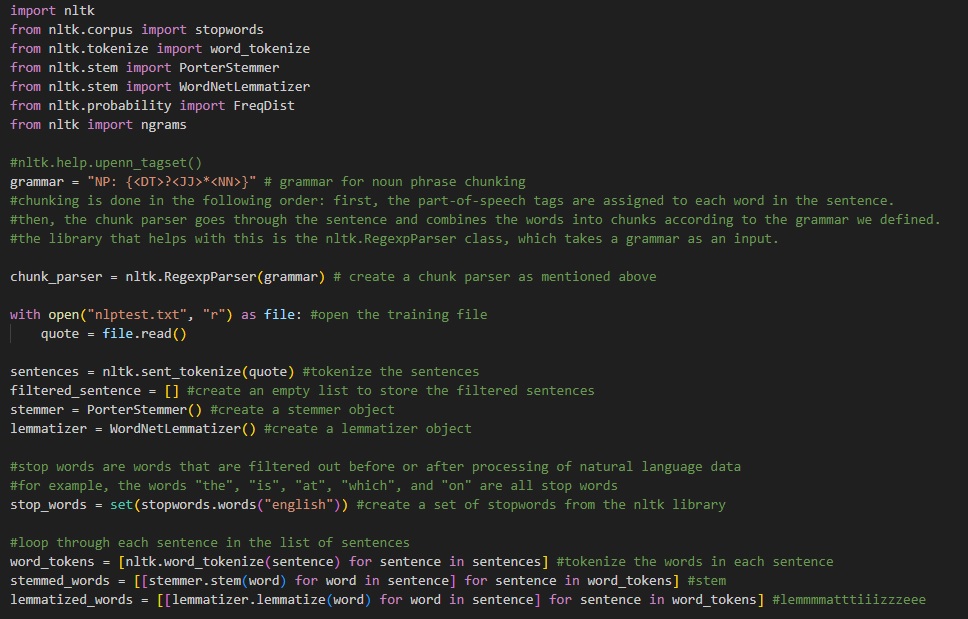
This is the initialization of all primary components in the program. As shown, variables are hyper specific to their usage -- some variables with direct correlation to NLTK's regexparser function and others as empty lists for their future implementation.
There are two or three letter terms such as "DT" or "JJ" or "NN" which are used in the NLTK to categorize specific words into different categories. Those categories are things such as "noun" or "adjective" or "verb".
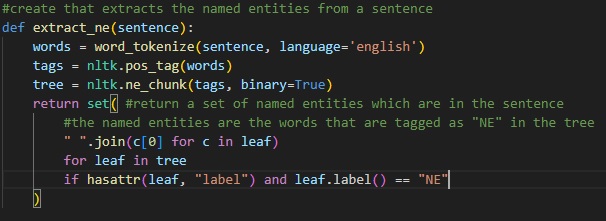
Here is the first function, the storing of NLTK's stop word library is best used to remove any "cold" words as I like to call them. Words that serve little functionality in the actual definition of the text. As listed in the comments, these words are the "is", "an", "which" that distract from the actual meaning of the text.
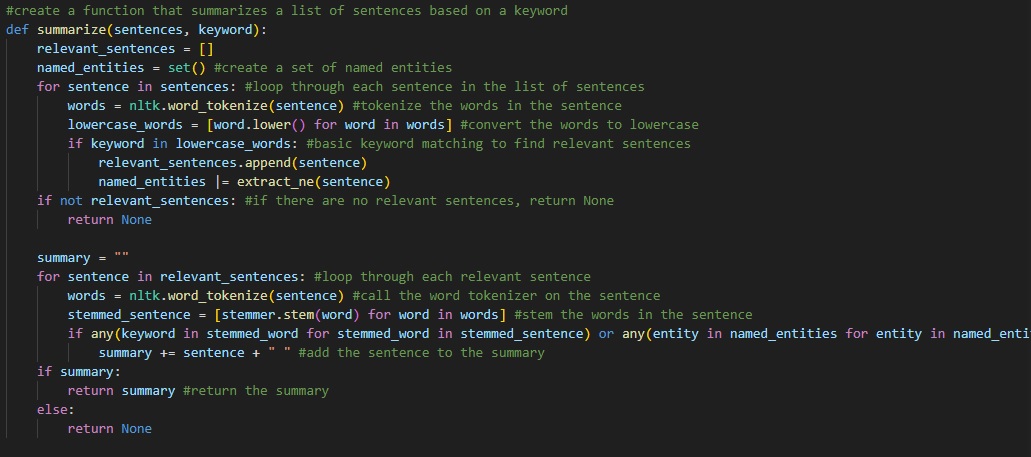
Following that is the first summarizing method function. In short, the function takes the keyword from the user's input and identifies that word throghout the text. Via cross-reference, the function then finds the sentence(s) that contain the keyword and stores them in a list. The list is then tokenized and broken down, formulating an exoskeleton of the sentence. The function then takes the sentence and compares it to the other sentences in the list, finding the most similar sentence. The most similar sentence is then stored in a new list, and the process is repeated until the keyword's temperature relieves.
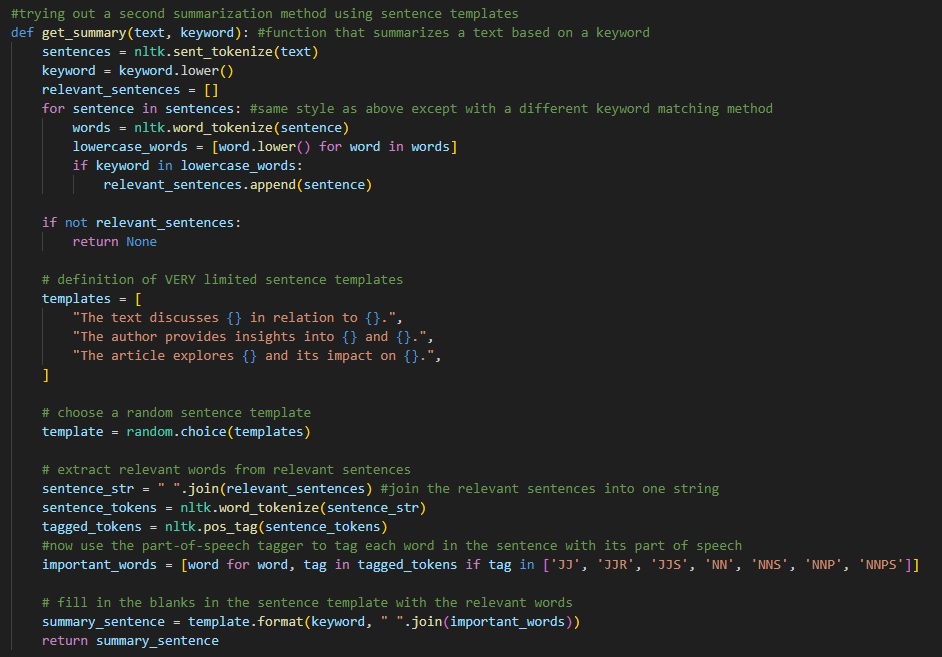
Now, this second method is similar to the first, except this time, uses a variety of sentence templates and the previously tokenized and lemmatized words to fill in and create the Natural Language aestheticism of the text. However, this method is not as efficient as the first, and is more of a proof of concept than anything else. Nevertheless, it was a fun challenge to implement.

Lastly, the output after user input. "log1" demonstrates the first function use case, and the other, the second function. As shown, the first function has difficulty limiting itself from exploding into word-salad, but provides core insight on the text. The second function identifies words of the highest temperature, at the cost of neglecting proper template usage. Fun project, and can definitely use modification down the line.
Back
C++ Snake
Written in pure C++, this game of snake I had created was a more robust, layman-esque project aimed towards demonstrating and harnessing the skills of C++'s object-oriented programming in part by game development.
My overall goal was to utilize the foundational knowledge of game development aspects in a text editor (VSCode) with the primitive SFML library to still create a game without the need for a game engine or dev software such as Unity, Unreal, or even smaller-scale envs like Godot.

The first step was to create global variables for the "tile-set" and arena. Alongside an enum class for the direction of the snake/player. Use enum over int for readability and ease of use.
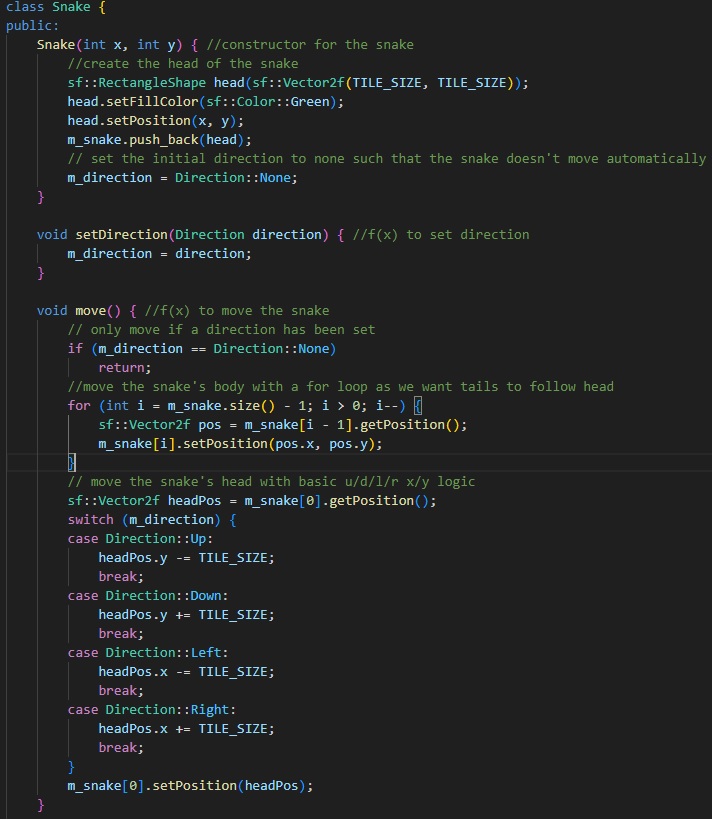
The snake class is an amalgamation of "sprite" creation, player function, and event handling packed into one. Using certain SFML specific elements, it is able to handle keyPress events and arena geneeration.
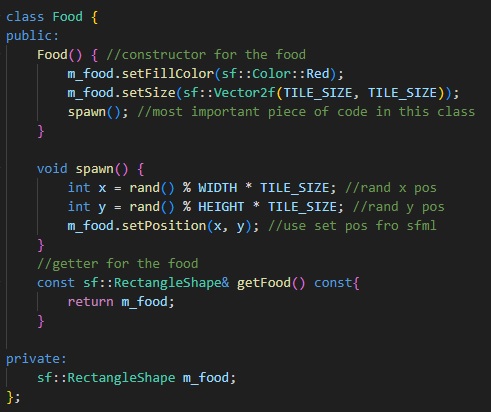
The food class is similar to the snake. Just as one would in a normal game editor, impose another child node to the parent and implement functions and handling in similar fashion.
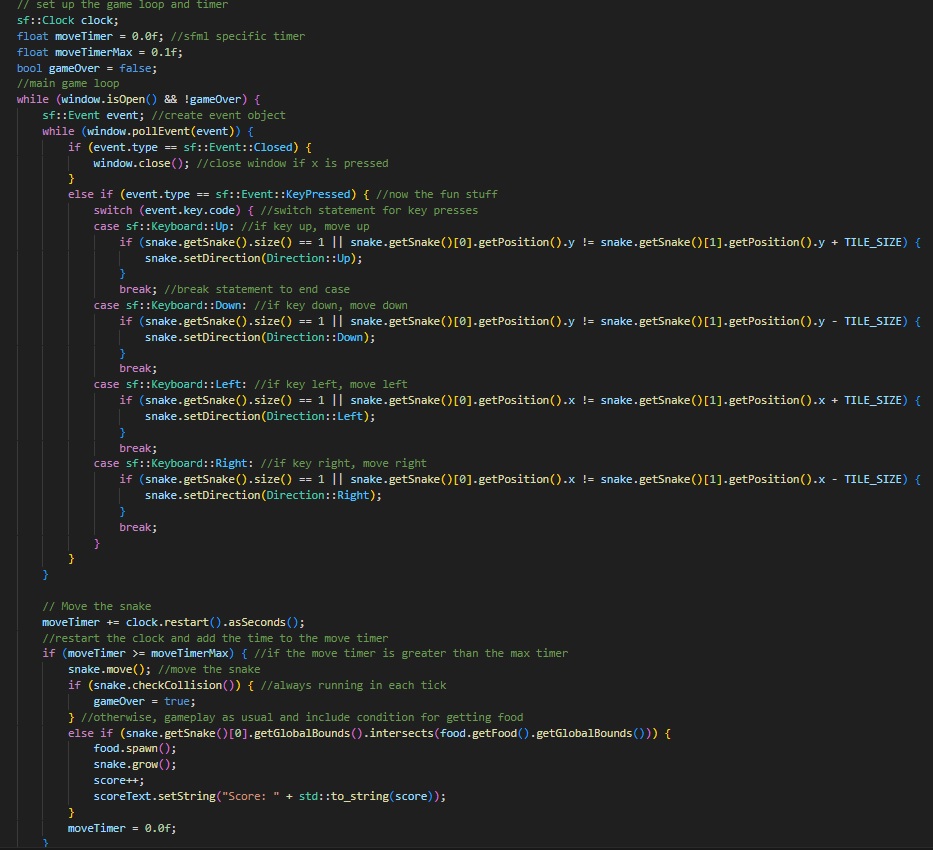
The main function consists simply of the main game loop and other practicalities required by the SFML library to render the window, and update frames.
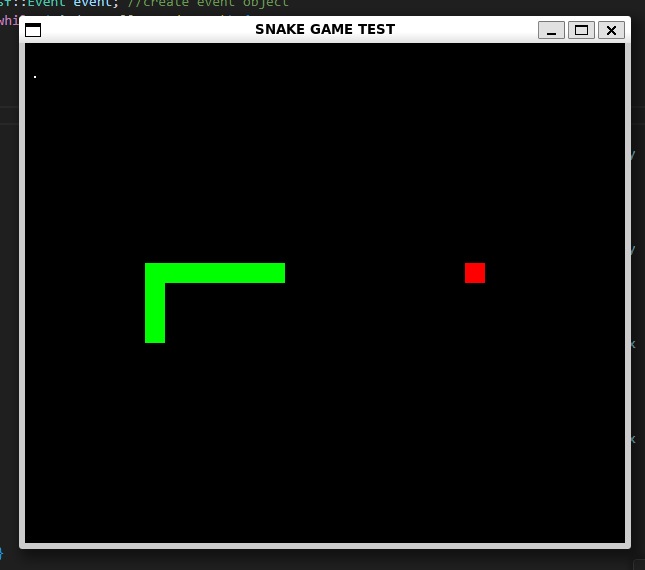
Finally, the rendered window, and a game of snake! As shown, sprite elements were drawn using basic rectangles and achieve their purpose. Food is red, green is player, and tail follows head and acts as a collision object! A holistic representation, a nootropic evolution of the barebones snake game.
Overall, this project taught well of the skeleton that consist of game development. Especially in its rawest , crude form. Much like how HTML acts as the barebones for web-dev, writing in C++ with this minimal framework in a text editor was a great learning experience on the practical elements in game development.